Platforms Are For Engineers, Not Services

Ask ten engineers what a "platform" or "platform engineering" is, and you'll likely get ten different answers. Crucially, most of those answers will focus solely on the tech stack, not on how people interact with the platform. This trend needs to change. Otherwise, we risk disgruntled platform engineers frustrated by how their platforms are used, platform users who see technology adoption as a burden, and leaders who question the value of investing in an internal platform at all.
What's a "Platform" Anyway?
The following is probably just another non-normative definition, but one I like to use.
A curated set of tools, services, capabilities, and enablement resources designed to streamline the software development lifecycle and operational processes within an organisation, facilitating the adoption of best practices and engineering standards.
That's a mouthful, and there's a lot to unpack. Let's start with how different groups interpret it:
- Platform Engineers focus on building and deploying "tools, services, and capabilities" using cutting-edge tech for efficiency and reliability.
- Product Engineers look for "enablement resources" to free them from what some consider the "boring platform bits" so they can deliver new, cool features.
- If you know any Product Leads you'll know the words "streamline the software development lifecycle" are music to their ears!
- SREs rely on "operational processes" to boost the efficiency and reliability of services deployed on the platform.
- Above all, Engineering Leads are keen on driving "best practices and engineering standards" to execute long-term strategy and increase cohesion across teams and codebases.
So, if you still think a successful platform is just fault-tolerant clusters, flexible traffic routing, or scalable telemetry pipelines, think again! Delivering infrastructure and tooling is only part of the story.
You might not feel like a product engineer, but your platform is your product! To truly reap the benefits of platform engineering, you need to step back and consider how people interact with your platform and how you can make their lives easier—and your systems better—by ensuring effective tool adoption. You need to start with the "why."
A Strategy Begins with a Diagnosis
One of the most influential books I've read in the last few years is Good Strategy, Bad Strategy by Richard P. Rumelt. It has shaped the way I approach large, complex initiatives across a range of domains. I truly recommend giving it a read. In essence, Rumelt uses his insight and experience across many fields and organisations to identify what makes a strategy successful. A key takeaway is the imperative to avoid "fluff", and to defer thinking of actions until one has clearly defined 1) the problem to solve, and 2) how the proposed future state will solve that problem.
To illustrate this, let's turn to my favourite domain: observability. I've often heard, "we have/need a strategy to adopt OpenTelemetry". While I deeply appreciate the sentiment—as I'd love the world to use OpenTelemetry—a strategy shouldn't just be "OpenTelemetry adoption". That's part of the implementation. The crucial question is: why are you adopting it? What problems are you trying to solve? Without understanding this, you risk critical gaps in your solution.

Below is a high-level example, inspired by Good Strategy, Bad Strategy, focusing on a specific aspect of OpenTelemetry adoption:
Diagnosis
Engineers struggle to correlate regressions in business KPIs with user experience, code changes, or backend service saturation. Teams operate independently in a "you build, you run it" model, but their lack of observability expertise leads to delays in detecting and resolving revenue-critical incidents.
Guiding Policies
- Use W3C Trace Context and W3C Baggage for context propagation across all services, so that telemetry data can be correlated through services that are part of the same user interaction.
- Auto-configure OpenTelemetry SDKs and contrib libraries to propagate standard context and to instrument known open-source libraries, so that minimal telemetry is produced out of the box to help engineers identify root causes of regressions, integrated with propagated context.
- Use OpenTelemetry APIs and Semantic Conventions to generate real-time telemetry for application-specific concepts, so that business KPIs can correlate to out-of-the-box telemetry emitted by the services involved in a given user interaction.
- Exercise debugging skills frequently, using observability tooling effectively, so that root cause analysis can be performed efficiently in the event of novel regression types.
Actions
- Build a base Docker image that contains a default declarative configuration for W3C propagators, and a minimal, extensible set of instrumentation libraries to guarantee context propagation.
- Template said declarative config with resource attributes obtained from environment variables that are automatically injected by deployment tooling.
- Use phased rollouts and automatically create pull requests to all services to adopt said base Docker image.
- Centralise training material and documentation to ensure engineers are set up for success when adding custom instrumentation using OpenTelemetry APIs.
- Create hands-on labs to showcase best practices in debugging systems using advanced tooling.
A comprehensive strategy may involve many interwoven diagnoses, guiding policies, and actions. Some policies might address multiple challenges, or a single action could implement several policies. Collectively, this approach explains not just the how, but crucially, the why.
So what?
When defining guiding policies, I find adding a "so what" aspect to each individually invaluable. It further clarifies the delivered value and directly links the guidance back to the problem it solves.
Notice how this strategy emphasises terms like "automatically" or "out-the-box," and includes actions that consider not only the tooling itself but also its rollout, adoption, and ultimately, effective engineer usage. Omitting these latter aspects would leave critical parts of the diagnosis unaddressed, such as the need for organisational standardisation paired with engineers' unfamiliarity with observability best practices.
Making the Golden Path the Path of Least Resistance
Perhaps I am stretching this concept by relating effective tech adoption to the Tao, but the Tao Te Ching's metaphors of water—adaptable, flexible, winding through terrain, yet powerful enough to erode stone—perfectly describe the engineering mindset.
As engineers, we are constantly seeking the path of least resistance. If we hit a wall, we'll spend precious time and effort building our own bypass, even if it means eroding the beautiful path you've laid out. So, if you genuinely want engineers to follow your best practices or engineering standards, you must make it the absolute easiest option. Make them ask, "why would I do it any other way?". Otherwise, you'll witness first-hand why "engineer" shares its root with "ingenious". They'll devise "wonderful" workarounds that, as you've guessed, rarely align with your standards.
My first encounter with this principle was at CERN, in Geneva. In 2011, I joined a small team to build DB On Demand: a scalable, self-serve system to automate creation and management of databases–MySQL, PostgreSQL, and later on InfluxDB–. We may not have used this term at the time, but that was textbook platform engineering.
Relatively fresh out of university and a Java developer by trade, the web UI aspect of my contributions was... rudimentary. But it worked, and its inherent simplicity had its benefits. You can read more about it in our DB On Demand paper published at the time in the Journal of Physics: Conference Series. You can also see part of that early UI below.
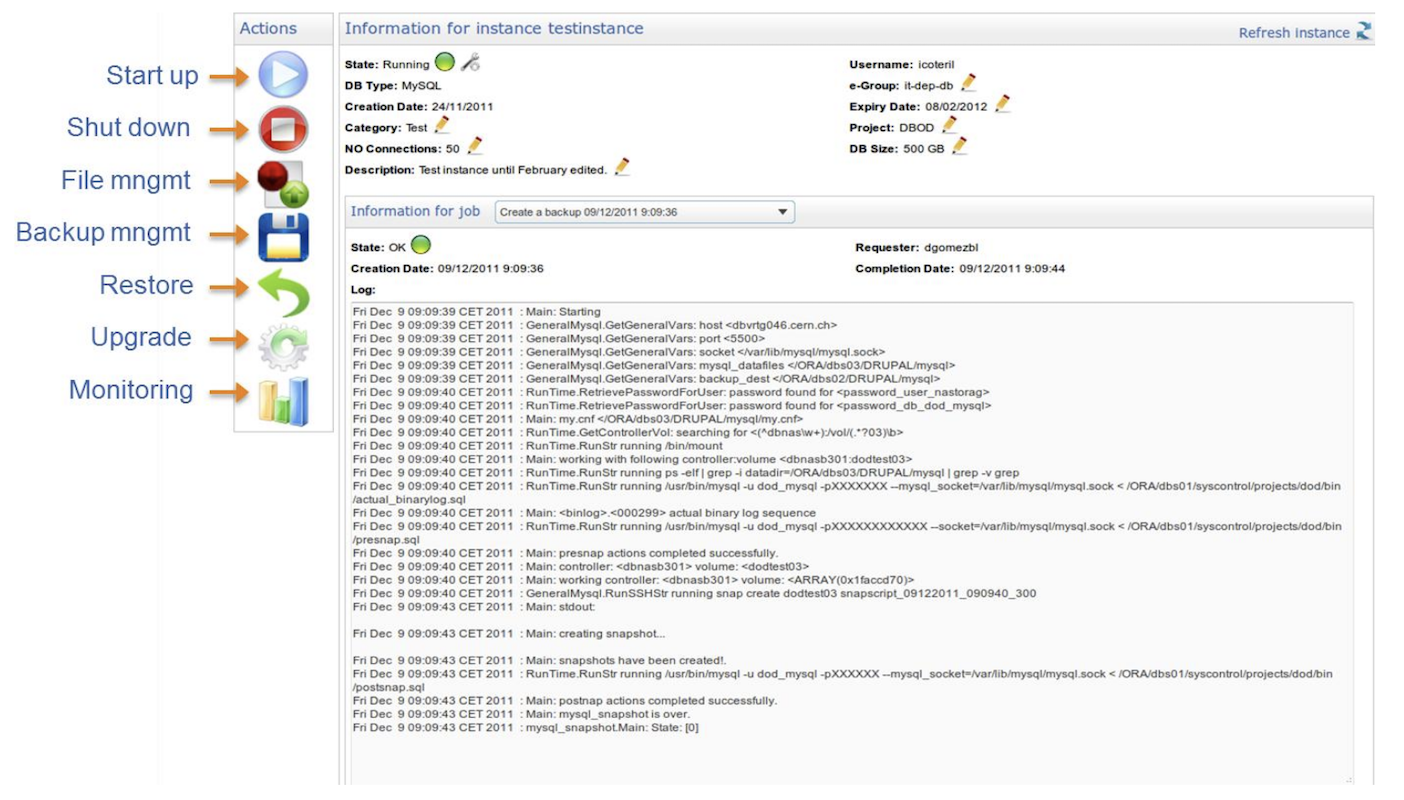
The core functionality was straightforward: database provisioning, one-click upgrades, automated snapshots, point-in-time recovery, basic monitoring, etc. The real magic, though, was its deep integration with CERN's world-class IT-DB group capabilities. For instance, users got, "for free", advanced features from underlying NetApp storage, like snapshots, thin provisioning, defragmentation, efficient RAID6, SSD cache—a dream for anyone who's ever wrestled with database management.
Within months of launch, we had dozens of databases and multiple teams onboarded. Today, DB On Demand has transformed (and thankfully, shed that "ugly UI," I'm told!), now hosting over 1,250 databases. Think about that: so many databases adhering to best practices, likely at a level unachievable if management processes weren't automated right out of the box. I mean, if you get database management for free... "why would you do it any other way?".
Opinionated, easily adoptable standards cultivate cohesive platforms and scalable architectures. This isn't just a benefit; it's a force multiplier, boosting velocity for product teams and accelerating the evolution of the underlying platform itself. For another example of this, checkout the following talk by Karan Thukral and Harvey Xia, from Reddit, at KubeCon NA 2024 in Salt Lake City, titled Evolving Reddit's Infrastructure via Principled Platform Abstractions.
Don't let the platform be a blocker
Default, auto-configured, opinionated standards don't imply that you should block any team that needs to deviate from those defaults for good reasons. In fact, you should welcome such input—it's how your platform truly improves! Read on for more on this topic.
Inverse Conway Manoeuvre to Synergise Platform and Enablement
Organisations which design systems are constrained to produce designs which are copies of the communication structures of these organisations.
That's Conway's Law. It's well known, but how does it apply to platform engineering? To explain this, I'd like to introduce another influential read: Team Topologies, by Manuel Pais and Matthew Skelton. Their website offers a concise summary of key concepts, including the vital roles of Platform and Enabling teams.
In the realm of platform engineering, "platform" and "enablement" are frequently—and often misleadingly—used interchangeably. Typically, "platform" denotes the infrastructure, while "enablement" refers to the tooling designed to ease its adoption. Yet, this presents a significant challenge: are you truly enabling other teams if your only contribution is a tool? Imagine handing a state-of-the-art drill to someone who's never held one; can you expect a clean job without proper training, practice, or support?
This is precisely the gap that Enabling teams, as defined by Team Topologies, are designed to bridge. These teams operate predominantly in a Facilitating interaction mode, working temporarily with other teams to elevate their skills in specific areas before moving on. In the context of our OpenTelemetry strategy above, this would be the team championing hands-on labs, training sessions, and other efforts to ensure all teams become proficient with observability tooling, enabling them to operate their services reliably and instrument their workloads according to best practices. Without this type of enablement, "shifting left" work is generally a recipe for disaster.
Back to Conway's Law. If we want to avoid a platform that's completely disconnected from the needs of its customers, which encourages teams to deviate from engineering standards, we need to exercise what's been popularised by this book as an Inverse Conway Manoeuvre. Effectively, instead of waiting for the team structure to shape the system, we should design team structures to match our desired architecture. Here, Platform and Enabling teams play a vital role to ensure that an internal platform can not only reduce toil and increase adoption of best practices, but also allow for it to evolve with the industry, meeting their customers' needs.
Platform teams, therefore, should concentrate on delivering capabilities "as-a-service". This includes tooling, opinionated configurations, or robust abstraction layers, defining their interaction patterns with other teams through an agreed-upon shared responsibility model.
In our OpenTelemetry example above, a Platform team could provide OTel distributions with sensible defaults that make applications "just work" upon deployment, or offer managed pipelines for seamless telemetry ingestion. However, service owners retain the fundamental responsibility for adding domain-specific telemetry to their system and leveraging it effectively for production operations. This is illustrated in the Team Topologies style diagram below.
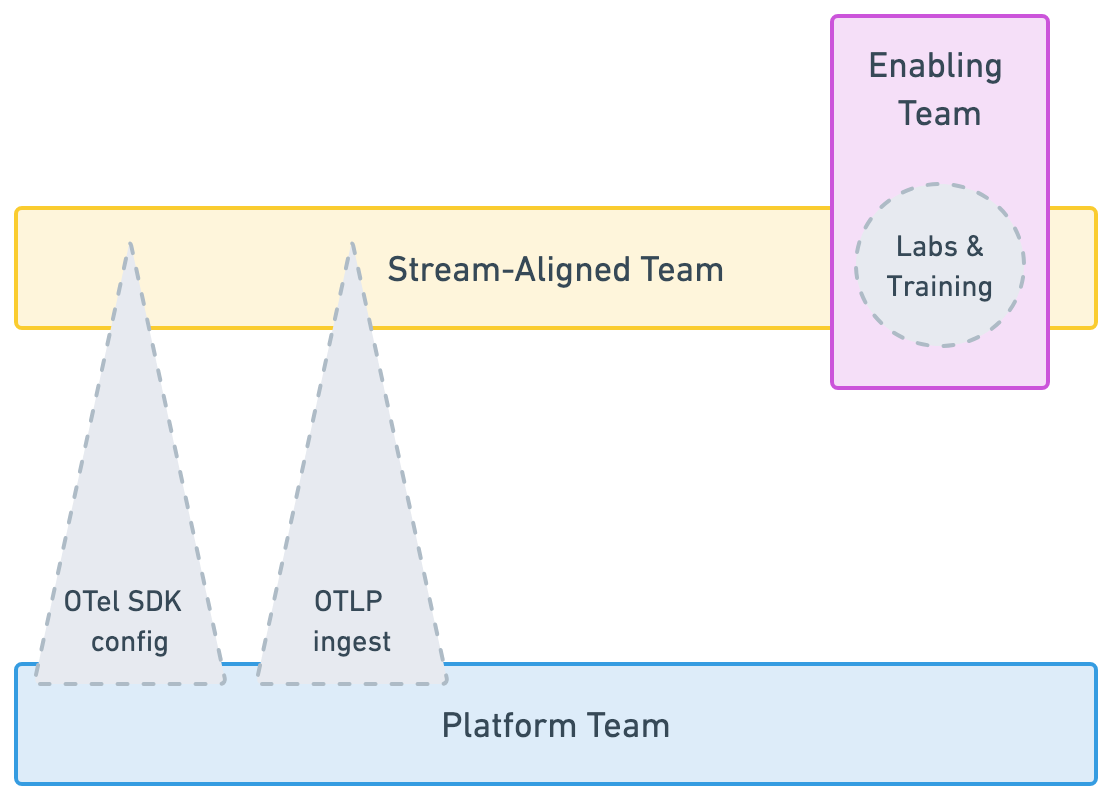
Why good cross-cutting API design matters
With an API design that decouples API interfaces from their SDK implementations, OpenTelemetry allows Platform teams to configure data aggregation, processing and export, empowering service owners to directly rely on the API layer within their codebase. Learn more about this in OpenTelemetry in 5 Minutes.
When a skill gap is identified by Platform teams, they can seek assistance from Enabling teams, who will facilitate skill development but not take ownership of the task. Conversely, Enabling teams can help identify gaps in tooling, and feed this information back to Platform teams to evolve the platform offering.
Known as interaction modelling, his concept is vital for aligning your team structures with your target architecture. Even if your organisation isn't large enough to have separate Platform and Enabling teams, and one team covers both roles, clearly mapping out these interactions and ensuring everyone understands them can significantly improve outcomes.
Now that we're onto agreed interaction modes between teams, the next step is measuring compliance with those agreements over time, be it a service or a tool. Something that can be modelled as SLAs/SLOs and engineering scorecards, but this blog post is getting too long, so I'll save that for a future time!